




I remember tweeting some time ago.
"As developers everything we do looks like magic to users. But a software that looks like magic to me is Git."
Of course, it did when I didn't know how git works. Git is like a developer's best friend. Git is software that tracks the changes in a repository that we are using git in. We can simply say that git is a directional graph that moves forward in time. It simply tracks the code being changed through time.
with this obvious stuff out of the way let's get into interesting stuff.
Note: If you are here for a tutorial on how to use git. There are many articles already explaining that and you're at the wrong address.
History of Git
Do you remember? before we know about git and when we are writing code, and we mess up something, we used to hit ctrl + Z until we reach the desired version of the code back in time. But we know Undo & Redo are not very efficient at tracking changes and the history of our code is short-lived. Version Control systems like git track and store the entire history of our code in an organised manner.
Git was first released in 2005, developed by Linus Torvalds (Yeah! The same legend who invented Linux, which is my favourite). At that time Linus was using a version control software called BitKeeper which was proprietary (now open-source). Due to some controversies, BitKeeper revoked access to the software of free users which lead Linus to develop his own, open-source version control software, git.
If you're familiar with the works of Linus Torvalds, he is a big fan of C, In which most of the Git is also developed.
Git is a distributed version control.
While version control solves the problem of tracking the history of code. To share or collaborate to code with others a central version control was introduced where code and its versions will be stored on a central system. If it goes down, the code is lost (assuming there is no backup). In distributed version control systems, every user has the whole history of code stored in their local systems along with the central server like Github (or Gitlab).
Working of Git
To understand git, the best way is to use it. Though it seems strange at the beginning it becomes intuitive as we use it. To understand its internal working, let's look into a .git folder. When you initialize git in a directory we can see a folder named ".git" is created, normally this folder is hidden, so we have to alter our settings to see hidden files. This .git folder contains all the information for git to work.
To understand this better... I suggest you open a .git folder on the side and explore it.
Some important things in this .git folder are
- hooks - This folder contains some example scripts created when git is initialized
- logs - This folder contains logs as the name suggests for every action done
- objects - Objects are some highly compressed files, which we'll discuss later
- refs - refs contains references to all local and remote branches.
- config - config contains configuration info like username
- head - this is a file referring to the current branch we are working on.
Let's go step by step.
When you go make changes to the code, stage them and commit them. For every commit and staging, new objects are added. Let us say we add a new file to our repository hello.py and wrote some code in it. Let's stage it using the git add command. Now as soon as we stage it. we can see new objects are created in .git/objects folder. And after committing we can see one more object added.
The objects as mentioned before are highly compressed files, compressed using zlib library. An object can be of three types blob, tree and commit. Blob is nothing but a compressed format of our files after we stage them. The tree is the object that tracks the file structure of the repository. This is referred to the all changed, added or deleted file objects which are blob objects. Now commit is when we write a commit message and refer to the tree object. It looks like...
Commit --> Tree --> Blob
Every commit also refers to its previous commit called parent.
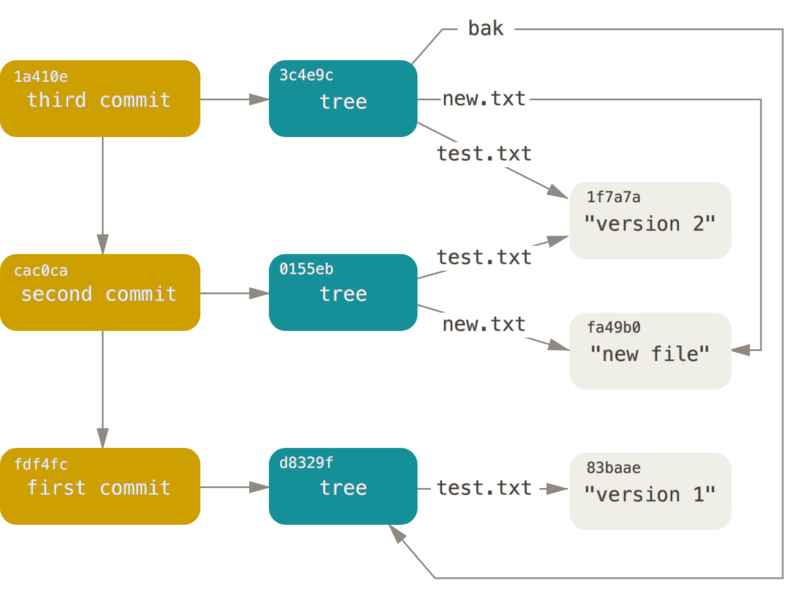
Every object is given a unique hash of type Sha1 of 40 characters long. They are stored in subfolders where the folder name is the first two characters of the hash. If an object has hash 8708e06876ef39d57366f66315c21b3e77c1c5b0 then a folder inside objects folder with name "87" is created in which object file named "08e06876ef39d57366f66315c21b3e77c1c5b0" is stored. That contains the compressed format of our files.
Whenever we run our git commands the software uses this information in the .git folder to do its work.
Conclusion
When we think of the internals of git we assume a complex software tracking all the changes. But in reality, git does some simple things like tracking flat compressed text files using references. We can imagine the web of references that git tracks in an average project.
Knowing the internal working of git made me realize that git is not magic. It made me appreciate it for what it really is... A very well written software. Something that still amazes me is how powerful and yet how atomic the software is. I really hope you'll appreciate git too the way I do.
PS
Thank you for reading this article. Though it's a complex topic... I tried to keep it as simple as possible. If you want to know more about this. Here is a great resource.